
On this page
AI is transforming how industries handle spare parts data by automating the process of reading nameplates. These small labels, found on machinery, contain crucial details like brand, part numbers, and serial numbers. Traditionally, manually recording this information is slow, error-prone, and inefficient - especially when dealing with poor lighting, dirty surfaces, or worn text.
AI-powered tools, combining OCR (Optical Character Recognition), computer vision, and machine learning, extract this data in seconds. They clean up images, identify text, and verify details against product catalogs. This process reduces errors, speeds up inventory management, and integrates seamlessly with ERP systems.
For example, tools like AutomaSnap simplify this workflow using just a smartphone. They cut data entry time from 10–20 minutes per part to less than 2 minutes, with accuracy rates exceeding 90%. This shift not only saves time and money but also improves reliability in spare parts management.
Unlocking AI OCR: Revolutionizing Text Recognition Technology
Technologies That Power AI Nameplate Reading
Successfully scanning nameplates relies on a mix of OCR (Optical Character Recognition), computer vision, and machine learning. Each of these technologies plays a unique role: OCR turns text in images into usable data, computer vision enhances image quality for better clarity, and machine learning adapts to the diverse formats of nameplates found in industrial environments. Together, they enable accurate and efficient data capture, even from difficult-to-read images.
Optical Character Recognition (OCR)
OCR is the technology that translates image-based text into machine-readable formats. Today’s OCR systems often use deep learning models, like Long Short-Term Memory (LSTM) networks, to identify characters on worn or damaged nameplates. The process includes detecting lines of text, identifying the language or script, and recognizing individual characters.
Recent advancements have introduced end-to-end models that combine text detection and recognition into a single step, improving efficiency and accuracy. However, as Adrian Rosebrock, PhD from PyImageSearch, points out, OCR systems often require customized pre-processing to handle tricky conditions like poor lighting or faded text. This is where computer vision steps in to prepare images for OCR, significantly boosting its performance.
Computer Vision for Image Preparation
Computer vision techniques clean up and optimize nameplate images before OCR takes over. These methods include:
- Binarization: Converting images to black and white to make text stand out.
- Deskewing: Straightening tilted text for better readability.
- Noise Reduction: Removing visual clutter or distortions.
Background removal is another critical step, isolating the nameplate from distracting elements like machinery or cables. Orientation and Script Detection (OSD) can analyze the text’s angle and style, correcting alignment issues before OCR begins.
Advanced neural networks also address common industrial challenges, such as dim lighting or partially obscured labels. By providing a clean and optimized image, these techniques ensure machine learning algorithms can handle the wide variety of nameplate designs with ease.
Machine Learning for Different Nameplate Formats
Machine learning builds on the work of OCR and computer vision to tackle the wide variability in nameplate designs. It enables AI systems to adapt to different fonts, layouts, and conditions. For instance, Transformer-based models like TrOCR are particularly effective in recognizing text under challenging conditions, such as unusual fonts or poor-quality images.
Vision-Language Models, such as GPT-4o and Florence-2, take this a step further by combining visual data with linguistic context. They can interpret abbreviations like “mfg” (manufacturing) and even predict missing details based on surrounding patterns.
Specialized tools like Surya focus on line-level detection and layout analysis, identifying complex structures like tables and headings in nameplate designs. The industry is also moving toward unified models capable of handling multiple languages and formats simultaneously. For niche applications, such as identifying automotive part numbers, fine-tuning open-source models often outperforms general-purpose commercial solutions.
How AI Processes Nameplate Images: Step by Step
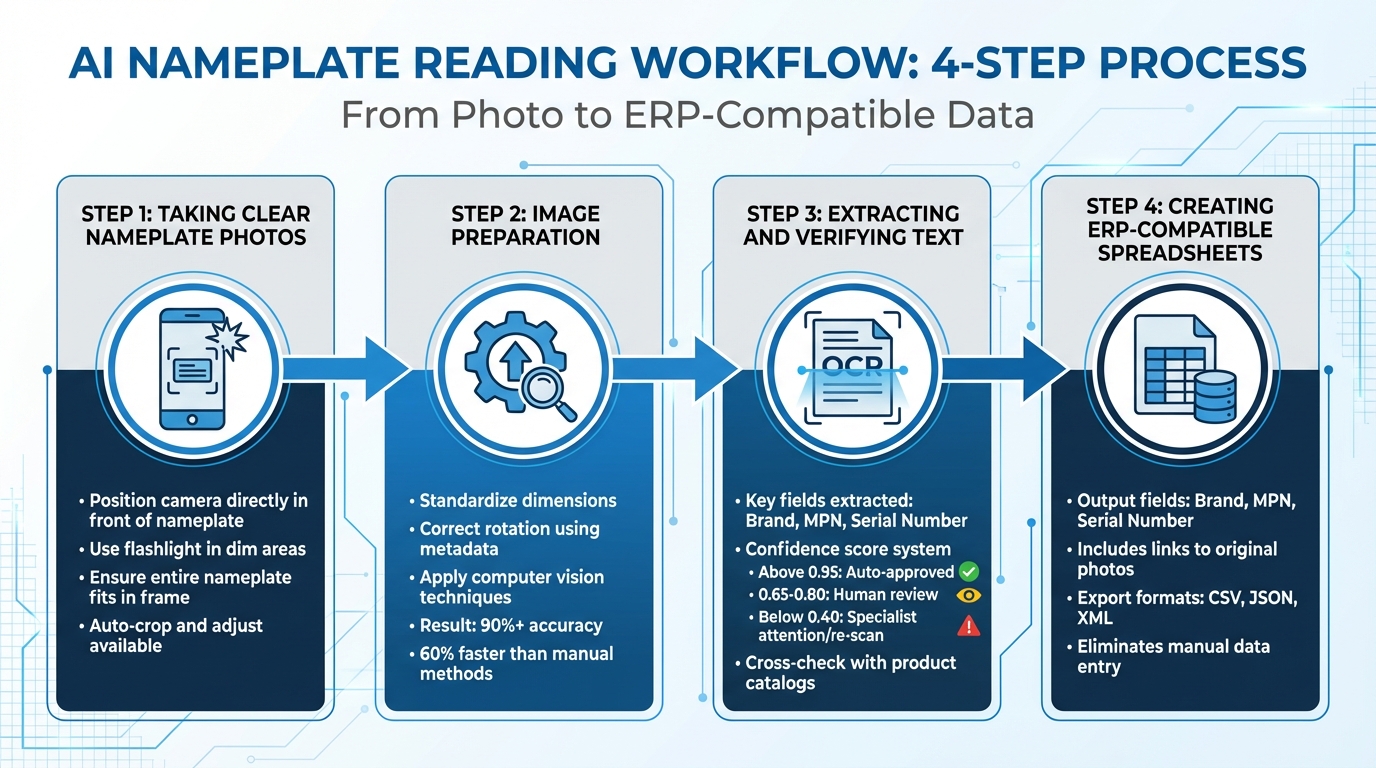
Understanding the journey from snapping a photo to generating structured data shows how AI turns a simple smartphone image into ready-to-use inventory details. This process blends practical photography techniques with automated enhancements and advanced data extraction. Here’s a breakdown of how AI handles nameplate images, from capture to ERP system integration.
Taking Clear Nameplate Photos
A sharp, well-lit image is the cornerstone of accurate data extraction. Start by positioning your smartphone camera directly in front of the nameplate. Technicians typically capture the nameplate as it is, without removing it from its location. Holding the phone steady and ensuring the entire nameplate fits within the frame are critical steps.
Lighting plays a major role in ensuring AI can accurately read the text. In dimly lit areas, such as tight mechanical spaces, a flashlight can make all the difference. Proper illumination helps the AI recognize text, especially on nameplates where the text and background lack strong contrast. Some smartphone apps can even crop and adjust photos automatically before they’re uploaded.
Image Preparation: Improving Quality
Once the photo is uploaded, AI steps in to optimize the image for processing. By standardizing dimensions and correcting rotation using metadata, the system ensures the image is aligned vertically, making it ready for analysis. This normalization process ensures consistency, even when photos are taken under different conditions.
AI then applies specialized computer vision techniques tailored to industrial settings. These enhancements not only improve the accuracy of text extraction - often exceeding 90% - but also speed up the process, reducing turnaround times by up to 60% compared to manual methods.
Extracting and Verifying Text Data
With the image prepped, the AI moves on to text extraction and verification. Using OCR (Optical Character Recognition), the system identifies key fields such as Brand, MPN (Manufacturer Part Number), and Serial Number. Each extracted field is assigned a confidence score, which determines the next steps:
- Scores above 0.95: Automatically approved.
- Scores between 0.65 and 0.80: Sent for a quick human review.
- Scores below 0.40: Flagged for specialist attention or a re-scan.
To ensure accuracy, the system cross-checks the extracted data with product catalogs, verifying that MPNs and serial numbers match the expected formats.
Creating ERP-Compatible Spreadsheets
Once verified, the data is organized into a format ready for ERP integration. The final output is a spreadsheet containing fields like Brand, MPN, and Serial Number, along with links to the original nameplate photos. This setup eliminates the need for manual data entry, significantly cutting costs.
The inclusion of the original photo in the spreadsheet serves as visual documentation, providing a reliable reference for quality control and future audits. This combination of structured data and photographic evidence ensures a seamless transition into inventory management workflows.
Solving Common Nameplate Reading Problems
Once image quality is optimized and data is extracted, AI still faces challenges with the imperfections found in real-world nameplates. These nameplates often come from outdated equipment, poorly maintained storage, or harsh industrial settings where dirt, grease, and wear are inevitable. AI systems are designed to work through these obstacles, ensuring accurate and reliable results.
Reading Damaged or Poor-Quality Images
Older nameplates often show signs of wear like scratches, fading, and contamination. As Marian Schlüter et al. from the Fraunhofer Institute explain:
The accurate identification of part numbers on dirty car parts is hindered by obscured characters and smudging caused by accumulated dirt and oil, presenting significant challenges for OCR systems.
To handle these issues, AI uses adaptive thresholding, which adjusts how light and dark areas are interpreted, even on unevenly lit or faded surfaces.
Training techniques also make a big difference. For example, the CharChan augmentation method swaps out detected characters with random ones during training. This helps the AI focus on recognizing actual character shapes instead of relying on context, which is critical for identifying random serial numbers. Specialized models like MaskedTextSpotter (MTS), fine-tuned on datasets featuring automotive and electrical parts, consistently outperform general-purpose OCR tools when dealing with worn or damaged components.
Processing Different Fonts and Layouts
Nameplates come in all shapes and styles - engraved serif fonts on motors, stamped sans-serif text on sensors, and more. AI handles this variety by using multi-model processing, which combines object detection, layout classification, and OCR. The process begins with locating the nameplate in the image and identifying its layout pattern. By recognizing these “format fingerprints”, the AI applies templates that pinpoint where details like Brand, MPN, and Serial Number are usually located, boosting accuracy.
For extra verification, the system cross-checks the extracted text with barcodes and pictograms on the same label. This layered approach also helps when nameplates are partially covered or obscured.
Extracting Data from Partially Hidden Nameplates
AI systems extend their capabilities to handle nameplates that are partially hidden. In industrial setups, nameplates are often positioned in tight spots where cables, brackets, or nearby components block parts of the text. To address this, AI uses template-based positioning to map the geometry of the label. This technique focuses on the relative placement of key fields, allowing the system to extract information even when parts of the nameplate are cropped or obscured.
End-to-end deep learning models like TextFuseNet combine text detection and recognition in a single process, making them especially effective for complex layouts and irregular shapes. These models analyze character fragments and use positional context within the label structure to reconstruct missing characters. When confidence scores dip below 0.65 due to obscured text, the system flags those entries for human review rather than making automatic decisions.
Using AutomaSnap for Nameplate Data Extraction
AutomaSnap simplifies the entire process of capturing and integrating nameplate data, saving time and reducing errors. By using cutting-edge AI, it slashes inventory intake time from 8–10 minutes per part to just about 1.5 minutes. Even better, it runs directly in your web browser with a standard smartphone camera - no need for extra apps or workflow changes.
Uploading Photos and Extracting Data
With AutomaSnap, getting started is straightforward. Take a photo of the nameplate using the web interface on your smartphone. The system immediately employs OCR (optical character recognition) and computer vision to extract key details like Brand, MPN, and Serial Number.
After the AI processes the image, technicians review and edit any fields flagged as low-confidence. This step ensures high accuracy, with OCR achieving between 90% and 98% precision compared to the roughly 4% error rate typically seen in manual data entry. Human oversight ensures any questionable fields are corrected quickly and effectively.
Creating Spreadsheets for ERP Systems
Once the data is verified, AutomaSnap automatically generates ERP-ready spreadsheets. These files, exportable in formats like CSV, JSON, or XML, are organized with fields for Brand, MPN, and Serial Number. This automation eliminates the 10–20 minutes per part usually spent manually entering and double-checking data.
For example, Gal-Industry adopted AutomaSnap to speed up their intake process, removing bottlenecks and enabling faster product listings on sales platforms. The pricing is competitive, too - around $0.55 per part for smaller batches (under 500) and $0.38 per part for larger monthly volumes (500+ parts).
Adding Photo Documentation and Market Data
Each spreadsheet row includes a photo of the original nameplate, creating a visual audit trail. Additionally, one-click links to eBay and Automa.Net are provided for instant access to pricing and demand research. This integration allows users to check market conditions directly within their workflow, making pricing decisions faster and inventory management more efficient.
Conclusion
AI-powered nameplate reading is reshaping inventory management by improving accuracy, speeding up processes, and integrating effortlessly with existing systems. While manual data entry often comes with a 7% error rate for serial number transcriptions, AI-driven OCR dramatically reduces these mistakes. Even a single typo can disrupt workflows and compromise system reliability.
These AI workflows also enhance technician productivity by 35% and can cut operational costs by up to 97%. What once took up to 30 minutes per asset to set up now takes less than 2 minutes.
Additionally, the shift toward mobile-first workflows makes implementation even more efficient. Modern AI tools can run directly in web browsers using standard smartphone cameras, removing the need for specialized equipment like barcode scanners and seamlessly fitting into current processes.
For distributors, asset recovery teams, and manufacturers, AI nameplate reading is transforming how inventory data is captured, verified, and integrated. With tools like AutomaSnap, these advancements come together in a single solution, redefining spare parts inventory management.
FAQs
What photo tips improve nameplate OCR accuracy?
Proper lighting is key for better nameplate OCR accuracy. Use consistent natural or artificial light to eliminate shadows and reflections. Make sure the camera is positioned perpendicular to the nameplate to avoid distortion. For clarity, aim for a resolution of at least 300 DPI or ensure the text height is at least 20 pixels. Keep the image sharp and in focus, steering clear of any blurriness or distracting backgrounds to achieve the best results.
How does AI verify extracted MPNs and serial numbers?
AI cross-checks extracted MPNs (Manufacturer Part Numbers) and serial numbers against databases, leveraging OCR (Optical Character Recognition) and pattern recognition. This approach ensures precise results, reduces manual mistakes, and boosts the reliability of the data.
When should low-confidence reads be reviewed by a person?
Low-confidence reads occur when an AI system isn’t completely sure about the accuracy of data extracted from nameplate images. In these cases, a manual review is essential. This step helps catch and correct any errors or ambiguities, ensuring the data remains accurate. By doing so, you can prevent incorrect information from being added to your inventory or ERP systems, safeguarding overall data quality.